
What Predicts the Best Data Science Salaries?
Using the job search aggregator Seek.com, I scrapped over 1,000 data jobs from Melbourne and Sydney. The resulting datasets were combined, cleaned and stored in a pandas DataFrame, which I used to identify what features are the best predictor of salary, and classify data science jobs.
Please click for the here for the full notebook.
Classifying data science jobs involved using Sklearns term-frequency-inverse-document-frequency (TFIDF) vectorizer to turn each word from the job posting text into a feature. I then used Sklearn’s Bagging Classifier with the Gradient Boosting Classifier, and was able to correctly classify data science jobs 88% of the time, and used a random forest model to identify the best and worse predicting words.
| best | worst |
|---|---|
| data | senior |
| business analyst | company |
| analytics | stakeholders |
| business | clients |
| machine | projects |
| delivery | analytical |
| analyst | role |
| learning | industry |
| process | highly |
| research | organisation |
Predicting data science salaries was a little less straight forward. While preforming EDA I noticed that senior level jobs in Melbourne are more positively skewed than in Sydney.
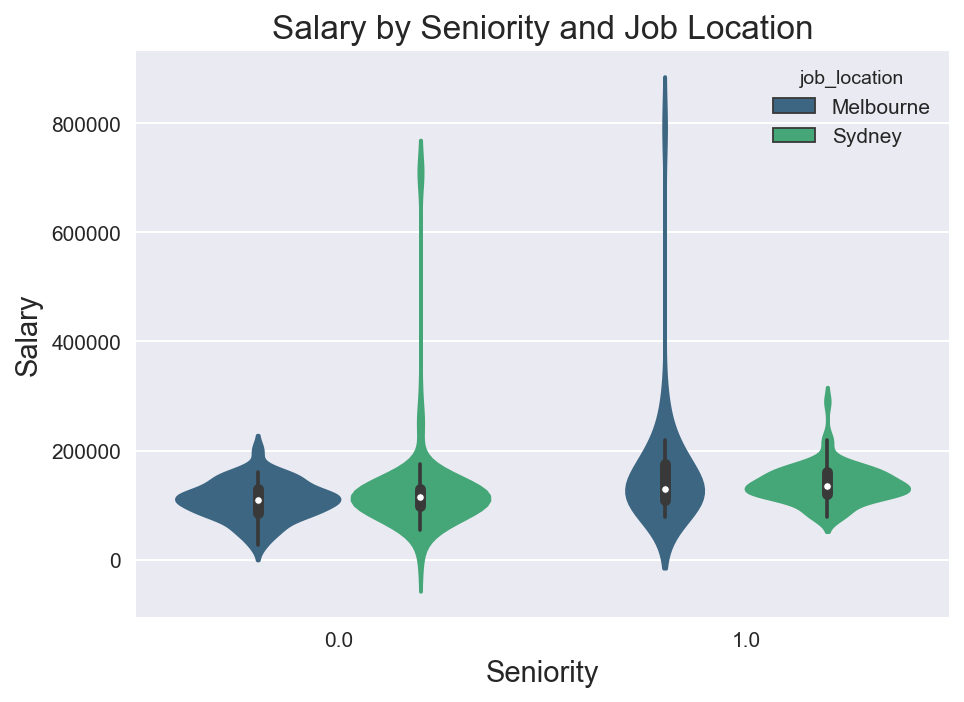
Taking this into consideration, I decided to use location (Sydney and Melbourne), seniority level, a length of the job description, and a tfidf vectorization of the description text as my features. This time I z-scored the non-tfidf features, and was able to explain 0.71% of the variance in job salary using Bagging Regression with Gradient Boosting Regression.